
Chunk Split
The Chunk Split component divides text or data into manageable chunks using various splitting strategies, with configurable chunk sizes and overlap options.
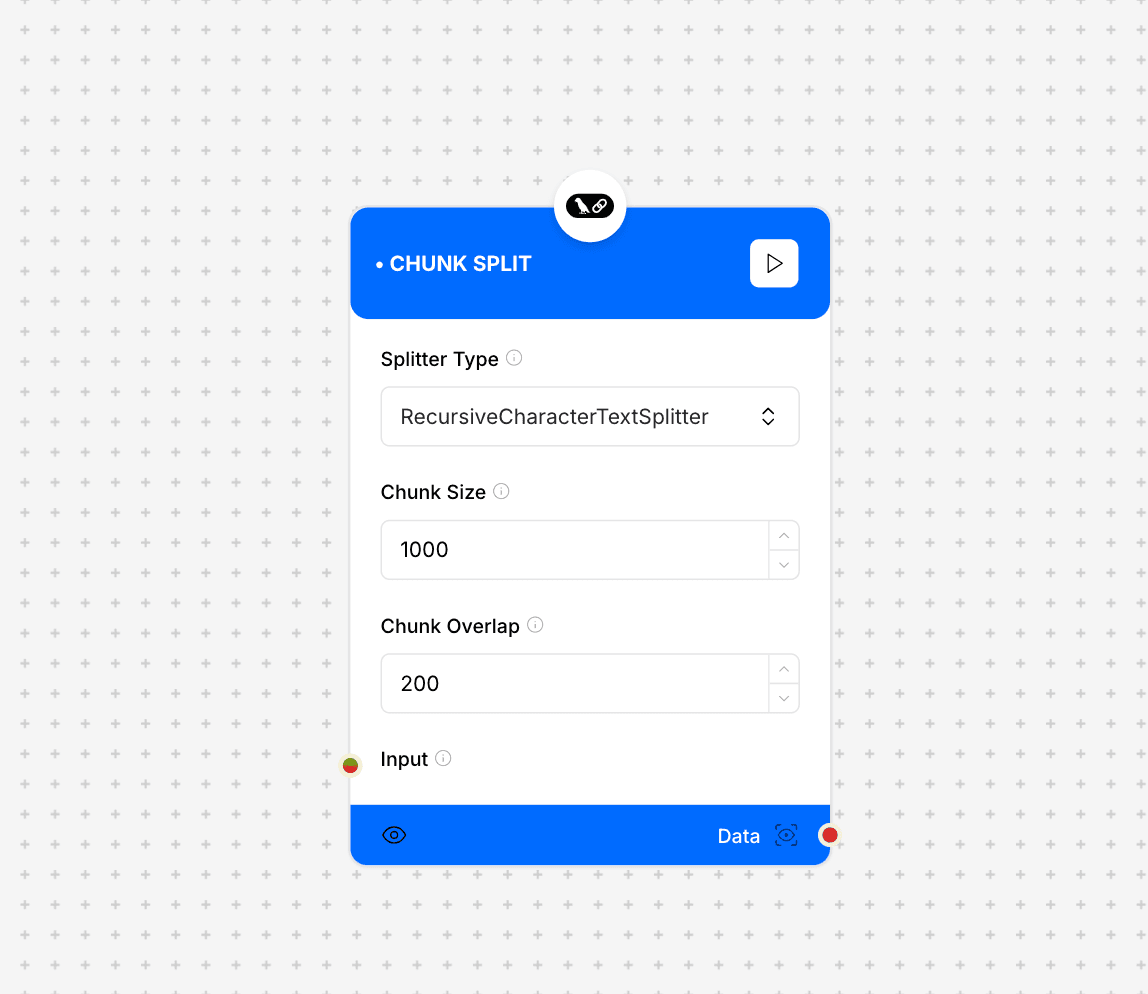
Chunk Split interface and configuration
Component Inputs
- Splitter Type: RecursiveCharacterTextSplitter
The type of splitting algorithm to use
- Chunk Size: 1000
The size of each chunk in characters
- Chunk Overlap: 200
The number of overlapping characters between chunks
- Input: Text or data to be split
The content to be chunked
- Separators: Custom separation points
Define custom split points in the text
- Code Language: python
The programming language for code-aware splitting
- Language: Additional language settings
Language-specific configuration
- Embeddings: Embedding configuration
Settings for embedding-aware splitting
Additional Parameters
- Breakpoint Threshold Type: percentile
Method for determining split points
- Breakpoint Threshold Amount: 0.5
Threshold value for splitting
- Number of Chunks: 5
Target number of chunks to generate
- Sentence Split Regex: Custom regex pattern
Regular expression for sentence splitting
- Buffer Size: 0
Size of the processing buffer
Component Output
- Data: Array of text chunks
The resulting chunks after splitting
Implementation Example
const chunkSplitter = {
splitterType: "RecursiveCharacterTextSplitter",
chunkSize: 1000,
chunkOverlap: 200,
input: "Long text content...",
separators: ["
", "
", " ", ""],
codeLanguage: "python",
breakpointThresholdType: "percentile",
breakpointThresholdAmount: 0.5,
numberOfChunks: 5
};
// Output:
// {
// chunks: [
// "First chunk of text...",
// "Second chunk with overlap...",
// "Third chunk with overlap..."
// ]
// }Additional Resources
Best Practices
- Choose appropriate chunk sizes based on content type
- Use meaningful overlap for context preservation
- Consider language-specific splitting for better results
- Test different separator patterns for optimal splitting