
EasyOCR Agent
The EasyOCR Agent is a powerful and user-friendly OCR solution that supports multiple languages and provides high-accuracy text extraction from images and documents. It offers a simple interface while maintaining robust recognition capabilities.
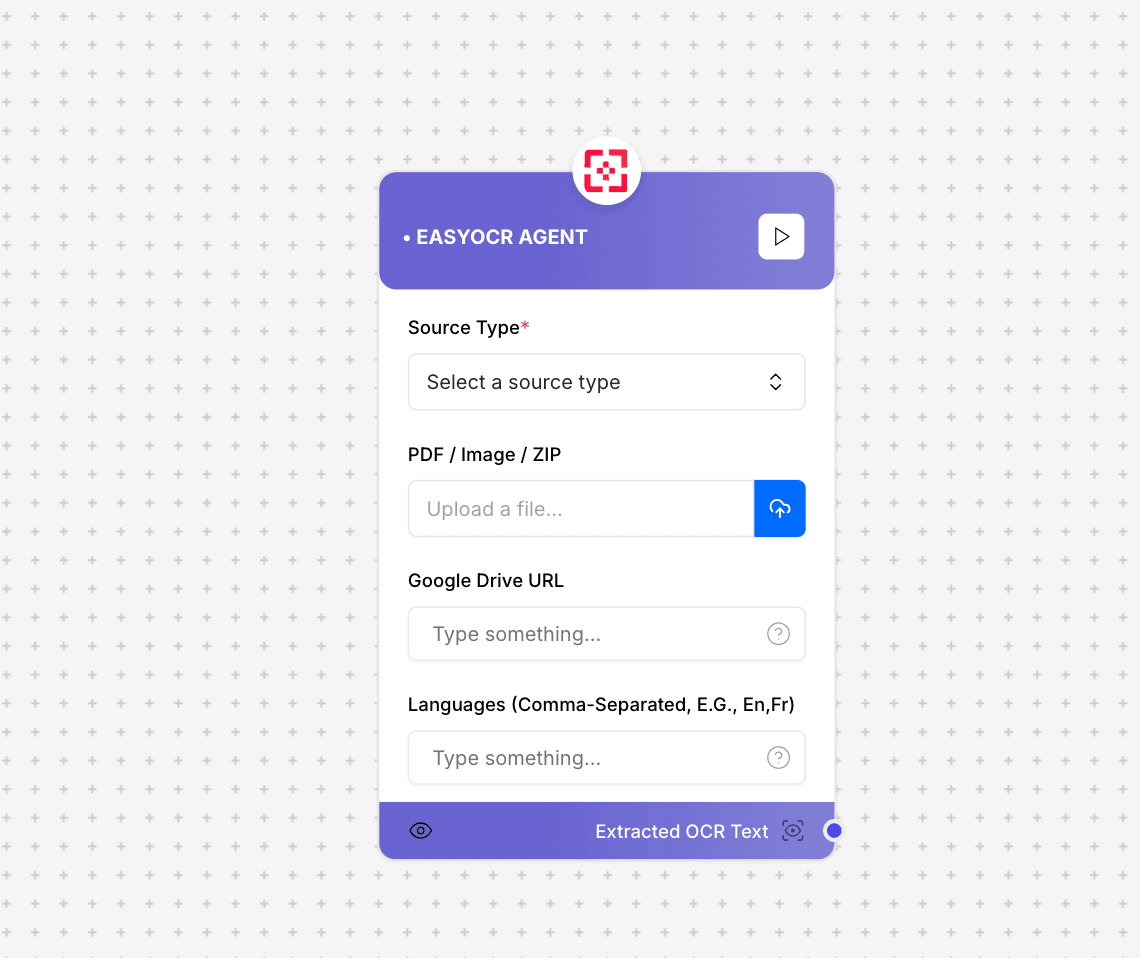
EasyOCR Agent interface and configuration
Language Support Note: Make sure to specify the correct languages in comma-separated format (e.g., "en,fr") for accurate text recognition. The first language specified will be treated as the primary language.
Component Inputs
- Source Type: Type of input source (PDF/Image/ZIP)
Select from available source types
- PDF/Image/ZIP: Upload your document file
Supported formats: PDF, PNG, JPEG, ZIP
- Google Drive URL: Optional URL to process files from Google Drive
Example: "https://drive.google.com/file/d/..."
- Languages: Comma-separated language codes
Example: "en,fr,es" for English, French, Spanish
Component Outputs
- Extracted OCR Text: The extracted text content from the document
Complete text extracted with layout preservation
How It Works
The EasyOCR Agent uses a deep learning-based OCR engine to recognize text in multiple languages. It processes documents in various formats and provides accurate text extraction with layout preservation capabilities.
Processing Flow
- Document input validation and format checking
- Image preprocessing and enhancement
- Text detection using deep learning models
- Multi-language recognition processing
- Text extraction and layout analysis
- Output formatting and delivery
Use Cases
- Multi-language Document Processing: Handle documents in various languages
- Batch Processing: Process multiple documents using ZIP archives
- Cloud Integration: Process documents directly from Google Drive
- Form Recognition: Extract text from structured forms and documents
- Image Text Extraction: Extract text from images and screenshots
Implementation Example
const easyOCR = new EasyOCRAgent({
sourceType: "PDF",
languages: "en,fr",
file: documentFile, // File object or path
googleDriveUrl: "https://drive.google.com/file/d/..." // Optional
});
const result = await easyOCR.processDocument();
// Output:
// {
// extractedText: "Processed document content with preserved layout...",
// confidence: 0.95,
// processingTime: "2.3s"
// }Best Practices
- Use high-quality input images for better recognition accuracy
- Specify the correct primary language for improved results
- Consider image preprocessing for poor quality documents
- Use batch processing for multiple documents
- Validate input file formats before processing