
Vertex AI Models
A drag-and-drop component for integrating Google Cloud's Vertex AI models into your workflow. Configure model parameters and connect inputs/outputs to other components.
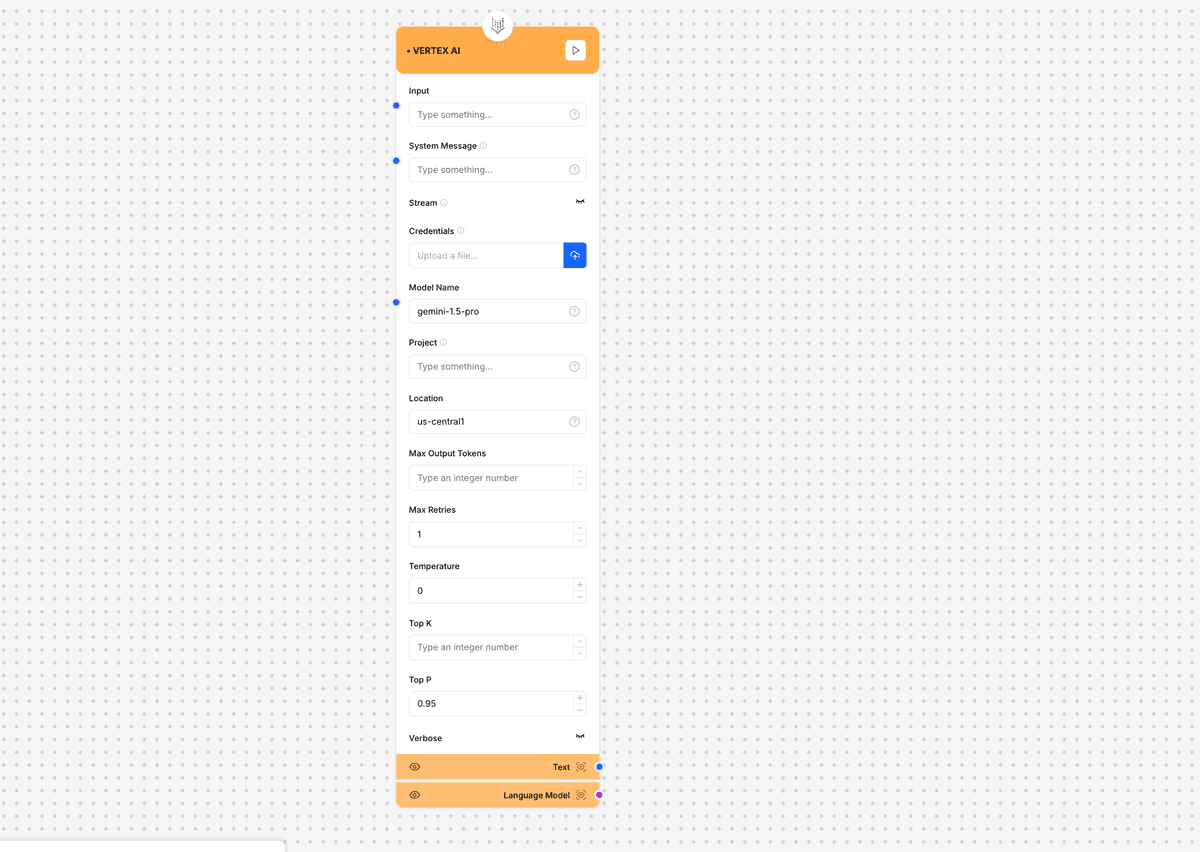
Vertex AI component interface and configuration
GCP Setup Required: This component requires a Google Cloud Platform account with Vertex AI API enabled and appropriate service account credentials. Ensure you have set up a GCP project and configured billing before using this component.
Component Inputs
- Input: Text input for the model
Example: "Explain how multimodal large language models work."
- System Message: System prompt to guide model behavior
Example: "You are a helpful AI assistant with expertise in machine learning and AI technologies."
- Stream: Toggle for streaming responses
Example: true (for real-time token streaming) or false (for complete response)
- Model Name: The Vertex AI model to use
Example: "gemini-1.5-pro", "gemini-1.5-flash", "gemini-pro"
- Credentials: Google Cloud credentials file
Example: Path to service account key JSON file
- Project: Google Cloud project ID
Example: "my-vertex-project-123456"
- Location: Region where Vertex AI is deployed
Example: "us-central1", "europe-west4"
Component Outputs
- Text: Generated text output
Example: "Multimodal large language models are AI systems that can process and generate content across multiple types of data..."
- Language Model: Model information and metadata
Example: model: gemini-1.5-pro, usage: {prompt_tokens: 50, completion_tokens: 180, total_tokens: 230}
Model Parameters
Max Output Tokens
Maximum number of tokens to generate in the response
Default: Model-dependent
Range: 1 to model maximum (varies by model)
Recommendation: Set based on expected response lengthTemperature
Controls randomness in the output - higher values increase creativity
Default: 0.0
Range: 0.0 to 1.0
Recommendation: Lower (0.0-0.3) for factual/consistent responses, Higher (0.7-1.0) for creative tasksTop K
Limits vocabulary for each generation step to k most likely tokens
Default: 40
Range: 1 to any positive integer
Recommendation: Higher values allow for more diversity in responsesTop P
Nucleus sampling parameter - controls diversity of generated text
Default: 0.95
Range: 0.0 to 1.0
Recommendation: Lower values (e.g., 0.5) for more focused text generationMax Retries
Number of retry attempts for failed requests
Default: 1
Range: 0 to any reasonable number
Recommendation: Increase for critical applicationsVerbose
Toggle detailed output logging for debugging
Options: true/false
Default: false
Recommendation: Enable during development and testingSupported Models
Gemini Models
Google's latest multimodal models
- gemini-1.5-pro: Most powerful model with 1M context window
- gemini-1.5-flash: Efficient model for faster responses
- gemini-pro: Earlier generation model
- gemini-ultra: Enterprise-focused model with advanced capabilitiesPaLM Models
Text-only models (older generation)
- text-bison: General purpose text model
- chat-bison: Optimized for conversational applicationsImplementation Example
// Basic configuration
const vertexAI = {
modelName: "gemini-1.5-pro",
project: "my-vertex-project-123456",
location: "us-central1",
credentials: process.env.GOOGLE_APPLICATION_CREDENTIALS
};
// Advanced configuration
const advancedVertexAI = {
modelName: "gemini-1.5-pro",
project: "my-vertex-project-123456",
location: "us-central1",
credentials: JSON.parse(process.env.GCP_SERVICE_ACCOUNT_KEY),
maxOutputTokens: 2000,
temperature: 0.2,
topK: 40,
topP: 0.95,
maxRetries: 3,
verbose: true,
stream: true
};
// Usage example
async function generateResponse(input) {
const response = await vertexAIComponent.generate({
input: input,
systemMessage: "You are an AI assistant specializing in technical explanations.",
modelName: "gemini-1.5-pro",
temperature: 0.1
});
return response.text;
}Use Cases
- Enterprise Applications: Build AI solutions with Google Cloud security and compliance features
- Multimodal Processing: Create applications that can understand and generate content with text and images
- Content Generation: Generate articles, summaries, and creative content
- Conversational Agents: Build sophisticated chatbots with context awareness
- Google Cloud Integration: Integrate with other Google Cloud services in a unified environment
Best Practices
- Use service account credentials with least privilege access
- Set appropriate region for lower latency based on your user locations
- Enable streaming for real-time responses in interactive applications
- Monitor API quotas and usage through Google Cloud Console
- Implement proper error handling with appropriate retry mechanisms
- Test with small token limits during development
- Consider using environment variables for credentials and project settings